CAP Theorem in System Design
In today’s world of cloud application development, there has been a push toward distributed computing. Long gone are the days when native applications had all of their business logic locally, or when server systems all lived in the same bare-metal machine. To understand how to build resilient cloud applications, we need to understand the theory behind distributed systems. In this blog post, we are going to dive into the 101 of system design: the CAP Theorem.
Guarantees in CAP Theorem
The CAP theorem stands for Consistency, Availability and Partition Tolerance Theorem. It states that every system can only provide two out of those three guarantees.
- CA System: a system of this type ensures that it can respond to every call and every read is guaranteed to have the latest write. Because it assumes that the subsystems will always be available, this system can only exist in monoliths with all its subsystems deployed in the same bare metal.
- CP System: is a system that can handle network failures while maintaining consistency with the data it handles. Because of this, it might not be available to respond at times.
- AP System: this system will always return a response, even on the event of network failures. The drawback is that the data it serves might not be the latest write.
A cloud application, for its very nature, is a distributed system. Hence, Partition Tolerance is a constant in cloud deployments (the application MUST assume that the network communication between components might fail). For this reason, any cloud application can only be either Consistent or Available.
In the real world, however, there is more granularity to this. We are now going to explain the different types of consistency and availability we can design our application with. It is important to take into account the use cases of our app and what trade-offs are admissable. For example, for a social network we might give a lot of importance to availability even if the feed our user gets does not have the latest write to the system. On the other hand, a bank really wants to have the balances very consistent to avoid double spending.
Types of consistency
There are three types of consistency in a system, depending on the guarantees it gives:
- Weak consistency: there is no guarantee that the latest write will ever be read, it might be missed completely. This is just a best effort approach. The best use for this type of consistency is usually real time applications.
- Eventual consistency: the latest write will be read eventually but maybe not immediately. We ensure that all states will be read even if there is delay. This is the best consistency for highly available systems.
- Strong consistency: it is guaranteed that a read will always get the latest write. This will affect the availability of the system.
We need to ensure we design the right amount of consistency for our application, there might be times where we don’t care to receive every single state and we can focus more on it being as available as possible, because that is what our users want. An example of this could be a videoconferencing app.
On the other hand, we expect social networks to always give us content, but we don’t want to wait until every single write has been 100% committed in order to get our timeline, it can wait a minute or two. This is where eventual consistency shines.
Finally, a system that is in charge of buying and selling shares in the stock market really wants the guarantee that its reads are always with the most updated version of the data. It relies on those reads to make important trading decisions.
Types of availability
We can ensure that a system is reliable and always ready to respond by making sure multiple instances of the same node are deployed (replication) and what strategy do we have to recover from a failure (fail-over).
Fail-over strategies
In the event of system failure, it stands for how is the system prepared for it and how it handles its restoration. It is solved by duplicating the same node in two ways:
- Active/Passive: only one node is actively working in production while the other is just sending heartbeats1 to the active one. If the active node fails, then the passive one will take over the responsibility and promote itself to active while the other resets. It might exist some downtime while the passive node notices the failure and takes over.
- Active/Active: both nodes are actively working in production and sending each other heartbeats. Downtime in event of failure is greatly reduced at the cost of more complex routing.
Replication strategies
Replication strategies are implemented in the part of the system that store state (databases, file servers…), because those are the most important and vulnerable parts. The whole idea is to replicate the data among several nodes to keep it safe from data loss while making it available for users. The question to answer is, how can we ensure that we replicate all the data and, at the same time, keep the system available? There are several ways to do this, each with different trade-offs:
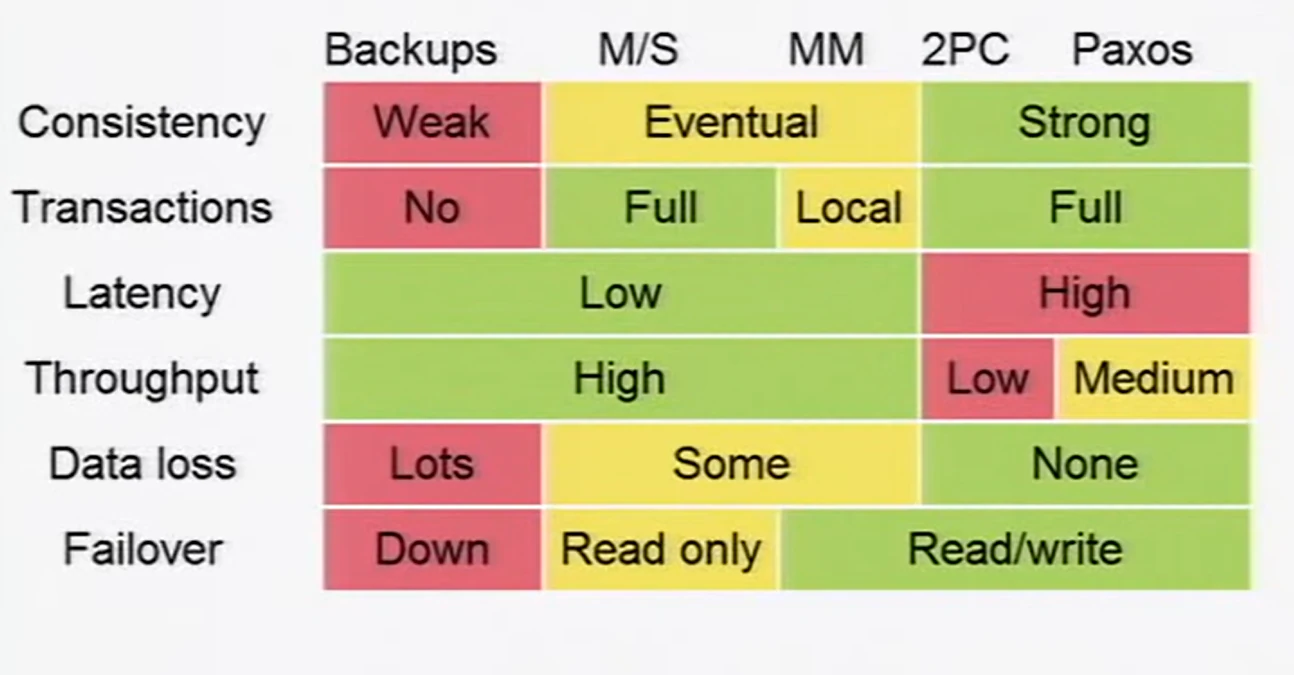 Source: Google I/O 2009 - Transactions Across Datacenters
Source: Google I/O 2009 - Transactions Across Datacenters
- Backups: this strategy can only ensure weak consistency. It takes a lot of time to copy the state at some point in time and, unless the system is taken offline while the backup is running, it will definitely miss data. Recovery with this system is slow as well since there is no second node ready to take over.
- Asynchronous replication: guarantees low latency and good throughput with eventual consistency.
- Master/Slave: one node is the master and the rest are dependant on the main one. The master node is the only one that accepts writes, that will be replicated asynchronously to all the slave nodes. The slave nodes only accept reads, and may not have the most recent writes. This ensures high availability at the expense of eventual consistency: slave nodes can be close to the users for read-intensive applications, but if someone wants to do a write must communicate to the master node. Because only one node accept writes, it is possible to do atomic transactions2 in this model. In case the master node goes down, fail-over is read only until one slave promotes to the new master, accepting writes again.
- Master/Master: all nodes accept writes and reads and replicate them to the other nodes asynchronously. High availability is maintained and writes are way faster. The drawback is that, because multiple nodes accept writes to the state, atomic transactions are not possible at the system level. Its a bit less consistent than Master/Slave. Because all the nodes are master, any node can take over the responsibilities of a failed one immediately, reducing downtime.
- Synchronous distributed consensus algorithms: guarantees strong consistency at the expense of latency and throughput.
- 2/3 Phase Commit: is an atomic commitment protocol that ensures all nodes in the system agree synchronously to the new write, hence maintaining strong consistency in the distributed system. The drawback of this type of replication is that availability is greatly diminished: every write must go through this consensus algorithm among every node in the system, potentially slowing down responses.
- Paxos: this is the most famous distributed consensus protocol, created by Leslie Lamport. It shares the same benefits and drawbacks as 2/3 phase commit, but has a bit better throughput. Is a family of different type of protocols, that even supports arbitrary failures in participants such as lying or fabrication of false messages (see Byzantine faults).
Conclusion
In this blog post we have explained the main characteristics of a distributed system and the main theory behind designing those systems. It is important to know about the trade-offs of the application you are working with and decide what CAP strategy to use. There is no silver bullet in engineering.
Check out the full Google I/O 2009 presentation about this topic. The speaker Ryan Barrett explains really well these concepts.
-
A heartbeat is a program that checks regularly if another system is up or down by sending small packets that must be acknowledged by the surveilled system to signal that it is online. If too many packets are sent without a response, the program alerts that the system is down. ↩︎
-
An atomic transaction is a set of operations that guarantees that either all occurs, or nothing changes. This ensures that if a system fails mid-transaction there won’t be any inconsistencies in the data because it will rollback any non-committed changes. ↩︎
